
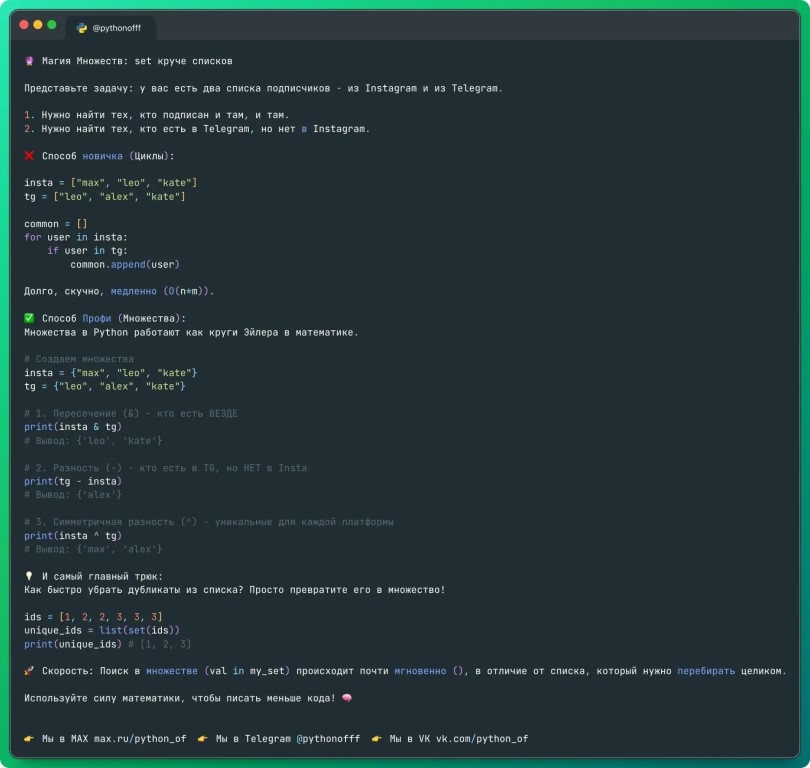
 🔮 Магия Множеств: set круче списков
Представьте задачу: у вас есть два списка подписчиков - из Instagram и из Telegram.
1. Нужно найти тех, кто подписан и там, и там.
2. Нужно найти тех, кто есть в Telegram, но нет в Instagram.
❌ Способ новичка (Циклы):
insta = ["max", "leo", "kate"]
tg = ["leo", "alex", "kate"]
common = []
for user in insta:
if user in tg:
common.append(user)
Долго, скучно, медленно (O(n*m)).
✅ Способ Профи (Множества):
Множества в Python работают как круги Эйлера в математике.
# Создаем множества
insta = {"max", "leo", "kate"}
tg = {"leo", "alex", "kate"}
# 1. Пересечение (&) - кто есть ВЕЗДЕ
print(insta & tg)
# Вывод: {'leo', 'kate'}
# 2. Разность (-) - кто есть в TG, но НЕТ в Insta
print(tg - insta)
# Вывод: {'alex'}
# 3. Симметричная разность (^) - уникальные для каждой платформы
print(insta ^ tg)
# Вывод: {'max', 'alex'}
💡 И самый главный трюк:
Как быстро убрать дубликаты из списка? Просто превратите его в множество!
ids = [1, 2, 2, 3, 3, 3]
unique_ids = list(set(ids))
print(unique_ids) # [1, 2, 3]
🚀 Скорость: Поиск в множестве (val in my_set) происходит почти мгновенно (), в отличие от списка, который нужно перебирать целиком.
Используйте силу математики, чтобы писать меньше кода! 🧠
Подписывайтесь на канал 👉 @python_of
🔮 Магия Множеств: set круче списков
Представьте задачу: у вас есть два списка подписчиков - из Instagram и из Telegram.
1. Нужно найти тех, кто подписан и там, и там.
2. Нужно найти тех, кто есть в Telegram, но нет в Instagram.
❌ Способ новичка (Циклы):
insta = ["max", "leo", "kate"]
tg = ["leo", "alex", "kate"]
common = []
for user in insta:
if user in tg:
common.append(user)
Долго, скучно, медленно (O(n*m)).
✅ Способ Профи (Множества):
Множества в Python работают как круги Эйлера в математике.
# Создаем множества
insta = {"max", "leo", "kate"}
tg = {"leo", "alex", "kate"}
# 1. Пересечение (&) - кто есть ВЕЗДЕ
print(insta & tg)
# Вывод: {'leo', 'kate'}
# 2. Разность (-) - кто есть в TG, но НЕТ в Insta
print(tg - insta)
# Вывод: {'alex'}
# 3. Симметричная разность (^) - уникальные для каждой платформы
print(insta ^ tg)
# Вывод: {'max', 'alex'}
💡 И самый главный трюк:
Как быстро убрать дубликаты из списка? Просто превратите его в множество!
ids = [1, 2, 2, 3, 3, 3]
unique_ids = list(set(ids))
print(unique_ids) # [1, 2, 3]
🚀 Скорость: Поиск в множестве (val in my_set) происходит почти мгновенно (), в отличие от списка, который нужно перебирать целиком.
Используйте силу математики, чтобы писать меньше кода! 🧠
Подписывайтесь на канал 👉 @python_ofЕсли у вас установлено приложение,
вы можете сразу перейти в канал